Introduction
Recently, I’ve been teaching myself a database course with materails from UC Berkeley’s CS 186 website, which has been an enjoyable experience so far.
Its second project is about B+ Tree implementation in the context of a buffered database management system. I’ve just gone through the implementation of this project and wanted to share a couple of thoughts and tips regarding B+ tree implementation.
A Quick Brush-up on B+ Tree
B+ tree is a ever-balancing tree-like data structure, meaning that no matter in what order the elements are inserted, the tree is always balanced. Each B+ tree has an order d, and the maximum capacity for each node is 2*d. Thus, the maximum number of branches for each non-leaf node is 2*d+1. Here’s an example of an order-1 B+ tree
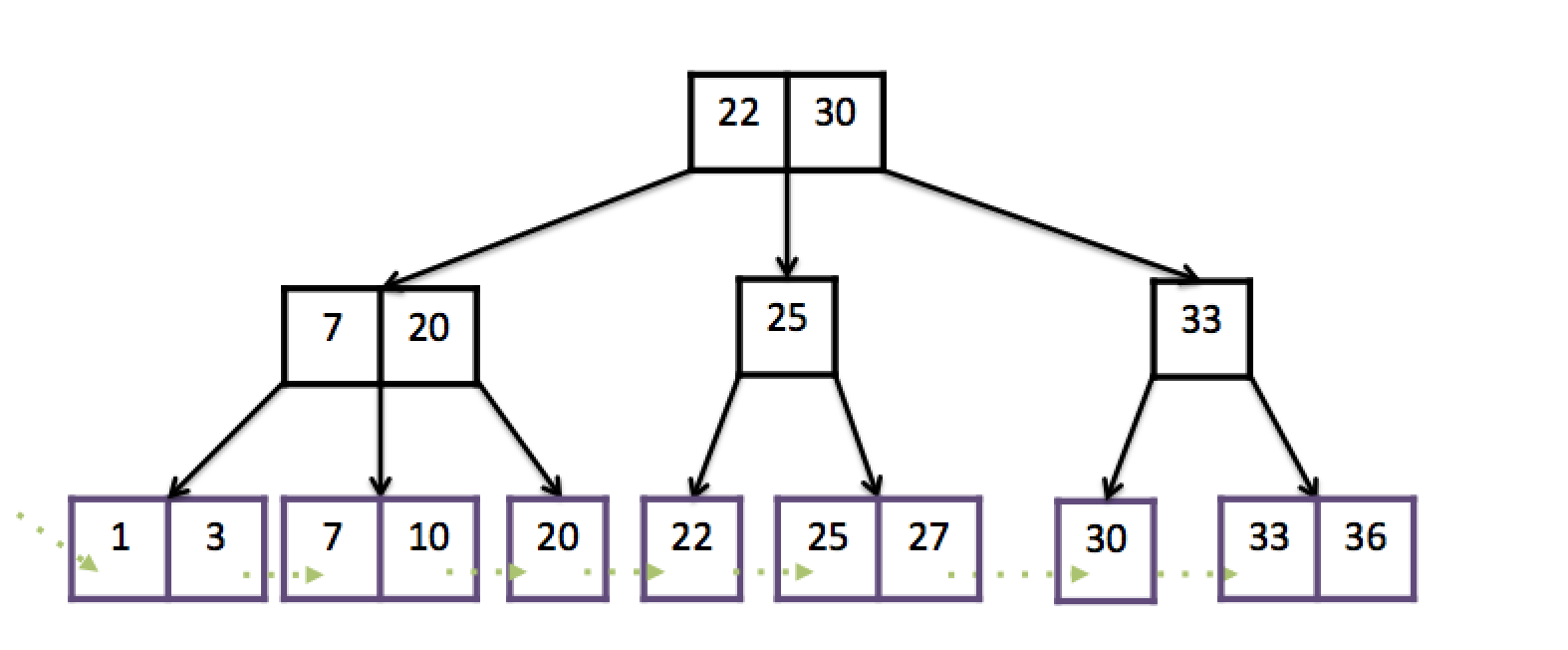
Each node in the B+ tree must be smaller than its “right parent” (if any) and larger than or equal to its “left parent” (if any). (*Here left and right denote the node to the left/right side of the current branch. For instance, 10’s left parent is 7 and its right parent is 20).
Two Types of Nodes
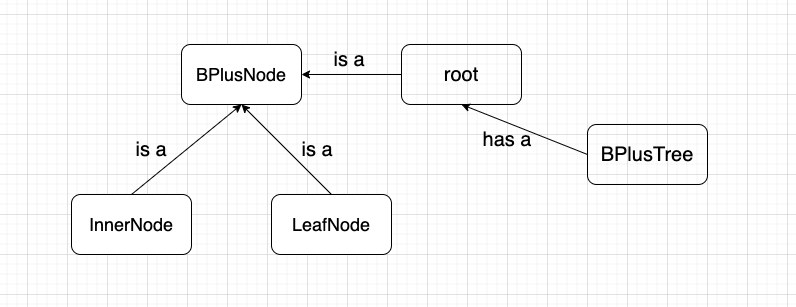
For the implementation purpose, considering only leaf nodes contain the actual data (the record id in this case) and non-leaf nodes only contain reference to its child nodes, we divide the nodes into two categories: InnerNode and LeafNode, both of which inherit from a base class called BPlusNode.
LeafNode
Nodes that actually contain the data (record id). It should have n keys and n record ids, where d <= n <= 2d.
Methods in the LeafNode class should be the base case for main methods in BPlusTree.
InnerNode
Nodes that serve as a roadmap for leafnodes. It should have n keys and n+1 branches, where d <= n <= 3d.
Methods in InnerNode class should be the recursive/iterative case based on the LeafNode case. They should be mostly ready to be called by root in the tree.
Buffer Manager
In a database management system, most data are stored on a hard drive or disk, and only a certain number of pages (the container for data and records) will be retrieved into the operating frames when needed. This mechanism is called buffer, and it’s managed by a series of cache algorithms like LRU cache (mostly simulated by a clock hand) or MRU cache.
Therefore, the node classes also need to have the ability to retrieve nodes from bytes serialized from the node information.
Upcoming sections
- the core API for the BPlusNode and BPlusTree class, including
- get
- getLeftmostLeaf (LeafNode and InnerNode only)
- put
- remove
- bulkLoad
- Tutorial for java 8+ Optionals and Pair
- Buffer management